云上运行 Hadoop 会面临哪些挑战
光环大数据作为国内知名的大数据培训的机构,聘请一流名师面对面授课、课程更新迭代速度快、与学员签订就业协议,保障学员快速、高效的学习,毕业后找到满意的高薪工作!
在云上运行Hadoop,很多人担心性能。因为一提到虚拟化就会有人想到有成本,往往得出有偏见的结论-在云上运行肯定比物理机器上运行性能差。确实,在云上运行Hadoop对平台方还是面临一些挑战的,下面主要讲述这些挑战及平台方怎么解决的。
前言
在云上运行Hadoop,很多人担心性能。因为一提到虚拟化就会有人想到有成本,往往得出有偏见的结论-在云上运行肯定比物理机器上运行性能差。如果单独把10台物理机虚拟化跑Hadoop,这肯定是有部分性能的开销的。但是如果在公共云上,情况就不是这样了。因为公共云虚拟化的开销最终是由平台方来承担的,其一是平台方采购机器有规模优势,其二平台方可以在保证虚拟机性能的情况超卖部分资源。
平台卖给用户8core32g的虚拟机就保证有这个规格的能力的。结合云上的弹性优势,企业的总体成本是会下降的。
在云上运行Hadoop对平台方还是面临一些挑战的,下面主要讲述这些挑战及平台方怎么解决的。

云上Hadoop的挑战-Shuffle
Shuffle分为Push模式,Pull模式。Push模式就是直接通过网络发送到下一个节点,比如:storm、flink。Pull模式就是数据先存储在本地,再启动下一个节点拉取数据,比如:Hadoop MR、Spark。
在push模式下,主要瓶颈点是网络。在一般的云环境中,网络跟线下没有太多的区别,可以满足需求。
在pull模式下,主要瓶颈点是磁盘。在云环境中,会提供本地磁盘或者用SDD加速的方案。如下:
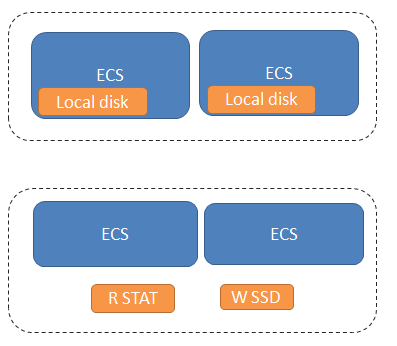
另外:
根据spark社区的报告,在机器学习等很多场景下,瓶颈点现在是CPU了
云上Hadoop的挑战-数据本地化
数据本地化含义是分析时,把计算移动到数据节点的。如果计算存储分离,则存在数据放在OSS中,需要从OSS远程拉取数据。一般情况下,认为这样会有性能问题。
当前,网络的带宽发展非常快:
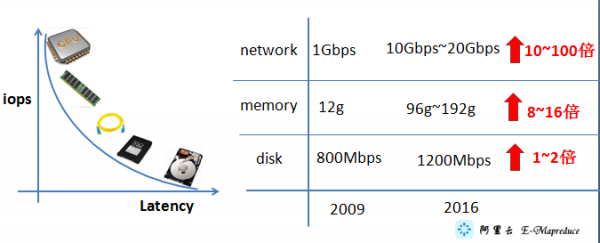
从09年到16年对比,大约带宽提升100倍左右,让大家影响深刻的是家庭带宽从4Mbps到了100Mbps了,4G也流行起来了,笔者现在基本不在电脑上存放电影,直接在线看的。现在很多机房在做100Gbps点到点的带宽。磁盘本身并没有太大的吞吐量的提升。还可以采取压缩算法把存储量减少。在 ETL场景下,往往只需要晚上运行数个小时,对性能本身不是太敏感;机器学习场景需要内存缓存数据;流式计算本身数据在移动的。
整体来讲,会随着带宽的增加、业务场景的实时化、多元化,数据本地化不是必须的。
云上Hadoop的挑战-自动化运维
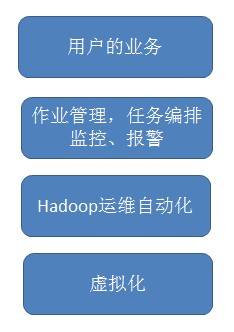
作业的管理、任务编排、监控、报警这些基本功能都还好。Hadoop本身非常复杂,如果Hadoop本身出现点什么问题,则会影响作业的运行。
这些问题包括但是不仅限于:
Master挂 各种日志清理等 节点挂掉,自动补回 Datanode掉线处理 NodeManager掉线处理 Job运行监控报警 负载过高监控报警 节点数据均衡 单节点扩容 版本自动升级 重要数据备份 Hbase等指标监控报警 Storm等指标监控报警
我们需要自动化诊断这些问题并在用户、平台的共同参与下把这些问题解决。
云上Hadoop的挑战-专家建议
是否需要扩容
Hive SQL,可以给SQL评分,给出最优写法
分析存储,比如:指明是否需要压缩;小文件是否过多,是否需要合并;访问记录分析,是否可以把冷数据归档处理
分析运行时各种JOB统计信息,如:Job的map时间是否过小,运行时reduce是否数据倾斜,单个job是否有一些参数调整
这个主要是针对存储、作业调优的,优化性能之类的。在一般企业内部是没有这套系统的。云上可以做成一套这样的系统,帮助广大的中小企业
大数据培训、人工智能培训、Python培训、大数据培训机构、大数据培训班、数据分析培训、大数据可视化培训,就选光环大数据!光环大数据,聘请专业的大数据领域知名讲师,确保教学的整体质量与教学水准。讲师团及时掌握时代潮流技术,将前沿技能融入教学中,确保学生所学知识顺应时代所需。通过深入浅出、通俗易懂的教学方式,指导学生更快的掌握技能知识,成就上万个高薪就业学子。 更多问题咨询,欢迎点击------>>>>在线客服!
